
自从去年ChatGPT发布以来,我一遍又一遍地听到同一件事的一些版本:这是怎么回事?聊天机器人和无穷无尽的“人工智能”应用程序的涌现已经清楚地表明,这项技术即将颠覆一切——或者至少颠覆某些东西。然而,即使是人工智能专家也有一种令人眼花缭乱的感觉:尽管人们都在谈论它的变革潜力,但这项技术的很多方面都隐藏在秘密之中。
这不仅仅是一种感觉。越来越多的人工智能技术,一旦通过公开研究开发出来,就几乎完全隐藏在企业内部,这些企业对他们的人工智能模型的能力和制造方式都不透明。法律上并不要求透明度,保密也带来了问题:今年早些时候,《大西洋月刊》披露,meta和其他公司在未经作者补偿或同意的情况下,使用了近20万本书来训练他们的人工智能模型。
现在我们有一种方法来衡量人工智能的保密问题到底有多糟糕。昨天,斯坦福大学基础模型研究中心发布了一个新的指数,追踪包括OpenAI、b谷歌和Anthropic在内的10家主要人工智能公司的透明度。研究人员根据开发人员是否公开披露100条不同的信息,对每家公司的旗舰模型进行了分级,比如它接受了哪些数据培训,向参与开发的数据和内容审核人员支付的工资,以及何时不应使用该模型。每披露一次就得一分。在满分100分的10家企业中,得分最高的企业勉强超过50分;平均是37岁。换句话说,每家公司都得到了响亮的F。
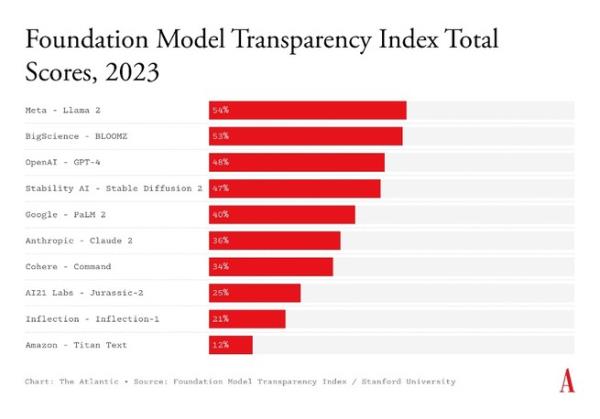
以OpenAI为例,它的命名是为了表明对透明度的承诺。它的旗舰模型GPT-4得分为48分,因为没有透露输入其中的数据、它如何处理可能在所述抓取数据中捕获的个人身份信息,以及生产模型使用了多少能量等信息,因此失去了重要的分数。就连一向以开放为荣、允许人们下载和调整其模式的meta也只得到了54分。加州大学伯克利分校(UC Berkeley)的人工智能问责研究员黛博拉·拉吉(Deborah Raji)没有参与这项研究,她说:“一种思考方式是:你正在烤蛋糕,你可以在蛋糕上添加装饰或图层。”“但你不会从食谱书中知道蛋糕里到底有什么。”
包括OpenAI和Anthropic在内的许多公司都认为,出于竞争原因或防止其技术的风险扩散,或两者兼而有之,他们对这些信息保密。我联系了斯坦福大学研究人员列出的10家公司。亚马逊发言人表示,该公司期待仔细审查该指数。拥抱脸公司的研究员兼首席伦理科学家玛格丽特·米切尔(Margaret Mitchell)表示,该指数错误地将BLOOMZ视为该公司的模式;它实际上是由一个名为“大科学”的国际研究合作项目生产的,该项目是由该公司共同组织的。(斯坦福大学的研究人员在报告中承认了这一点。出于这个原因,我在上面的图表中将BLOOMZ标记为BigScience模式,而不是hug Face模式。)OpenAI和Cohere拒绝了置评请求。其他公司都没有回应。
斯坦福大学的研究人员根据多年来现有的人工智能研究和政策工作选择了100个标准,重点关注每个模型的输入、模型本身的事实以及最终产品的下游影响。例如,该指数参考了学术和新闻对帮助完善人工智能模型的数据工作者的低薪酬的调查,以解释它的决定,即公司应该说明它们是否直接雇用这些工人,以及它们是否实施了任何劳动保护措施。该指数的主要创造者里希·邦马萨尼(Rishi Bommasani)和凯文·克里曼(Kevin Klyman)告诉我,他们试图记住对一系列不同群体最有帮助的披露类型:对这些模型进行独立研究的科学家、设计人工智能监管的政策制定者,以及决定是否在特定情况下使用某个模型的消费者。
除了对特定车型的洞察,该指数还揭示了整个行业的信息差距。研究人员评估的任何一个模型都没有提供关于它所训练的数据是否有版权保护或其他限制其使用的规则的信息。也没有任何模型披露足够的关于作者、艺术家和其他人的信息,他们的作品被刮掉并用于培训。大多数公司也对其模型的缺点守口如瓶,无论是他们根深蒂固的偏见,还是他们编造事实的频率。
每家公司的表现都如此糟糕,这是对整个行业的控诉。事实上,AI Now Institute的执行董事安巴·卡克(Amba Kak)告诉我,在她看来,这个指数还不够高。她告诉我,这个行业的不透明是如此普遍和根深蒂固,即使是100个标准也不能完全揭示问题所在。透明度并不是一个深奥的问题:拉吉告诉我,如果公司不全面披露信息,“这是一种片面的叙述。”而且几乎总是乐观的说法。”
2019年,拉吉与人合著了一篇论文,表明几种面部识别产品,包括出售给警方的产品,在女性和有色人种身上效果不佳。这项研究揭示了执法部门使用错误技术的风险。截至8月,美国已经发生了6起警方基于有缺陷的面部识别错误指控他人犯罪的案件;所有被告都是黑人。拉吉说,这些最新的人工智能模型也带来了类似的风险。在没有向政策制定者或独立研究人员提供审计和支持企业主张所需的证据的情况下,人工智能公司很容易夸大自己的能力,导致消费者或第三方应用程序开发人员在刑事司法和医疗保健等关键领域使用有缺陷或不充分的技术。
在整个行业的不透明中,很少有例外。索引中没有包含的一个模型是BLOOM,它与大科学项目类似(但与BLOOMZ不同)。BLOOM的研究人员进行了迄今为止为数不多的大规模人工智能模型对更广泛环境影响的分析之一,并记录了有关数据创建者、版权、个人身份信息和训练数据的源许可的信息。这表明,这种透明度是可能的。但Kak告诉我,不断变化的行业规范需要监管指令。她说:“我们不能依靠研究人员和公众拼凑出这张信息地图。”
也许最大的决定性因素是,追踪者发现,所有公司在“影响”标准方面的披露都特别糟糕,其中包括使用其产品的用户数量、基于该技术构建的应用程序以及这些技术部署的地理分布。这使得监管者更难以追踪每家公司的控制和影响范围,并追究它们的责任。对于消费者来说也更加困难:如果OpenAI技术正在帮助你孩子的老师,帮助你的家庭医生,并为你的办公室生产力工具提供动力,你可能甚至都不知道。换句话说,我们对这些我们将要依赖的技术知之甚少,我们甚至不知道我们有多依赖它们。
当然,保密在硅谷并不是什么新鲜事。近十年前,科技和法律学者弗兰克·帕斯夸莱(Frank Pasquale)创造了“黑箱社会”(black-box society)这个词,指的是科技平台在巩固其在人们生活中的主导地位的同时,变得越来越不透明。他写道:“保密正接近临界点,我们对关键决定一无所知。”然而,尽管来自其他人工智能技术和社交媒体的警示故事层出不穷,但许多人已经习惯了使用黑匣子。硅谷花了数年时间建立一个新的、不透明的规范;现在它只是被接受为生活的一部分。
为您推荐:
- 报纸上说的——五月十二日 2025-07-18
- 物理和化学防晒霜:你应该选择哪一种? 2025-07-18
- 菲律宾男子组合SB19宣布新的迪拜演唱会日期 2025-07-18
- 我们并不知道人工智能是否正在接管一切 2025-07-18
- 历史上的今天:12月4日,“百万美元四重奏”在孟菲斯录制了传奇唱片 2025-07-18
- 尤尔根·克洛普列举了他在利物浦统治时期最喜欢的进球、表现和助攻 2025-07-18


